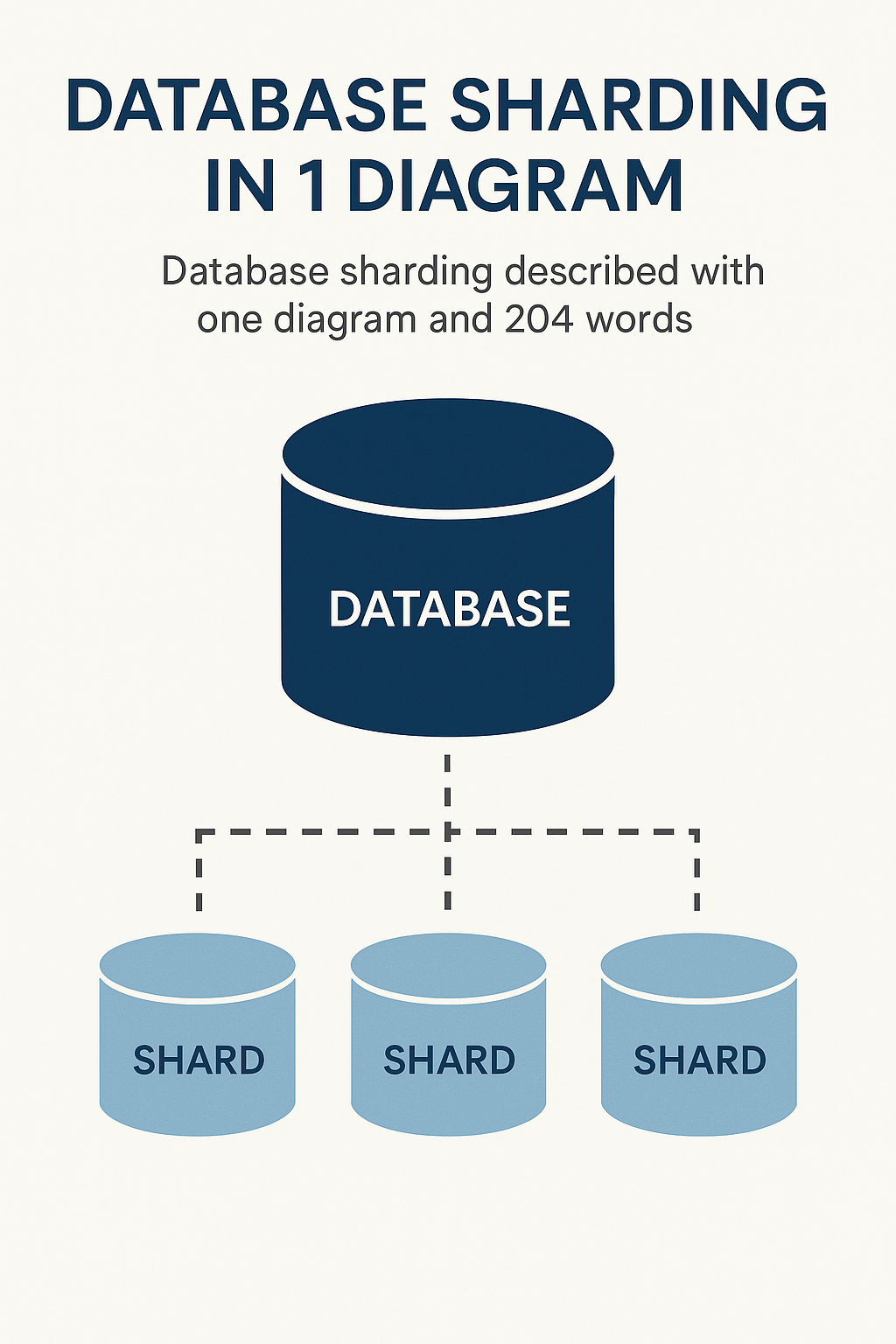
A technique that splits a large database into smaller, independent parts (shards) to distribute data across multiple servers.
As applications scale and databases grow, a single database server can become a bottleneck. Sharding helps scale horizontally by spreading data across multiple machines, improving performance and availability.
Use it when a single database cannot handle the read/write load or data volume.
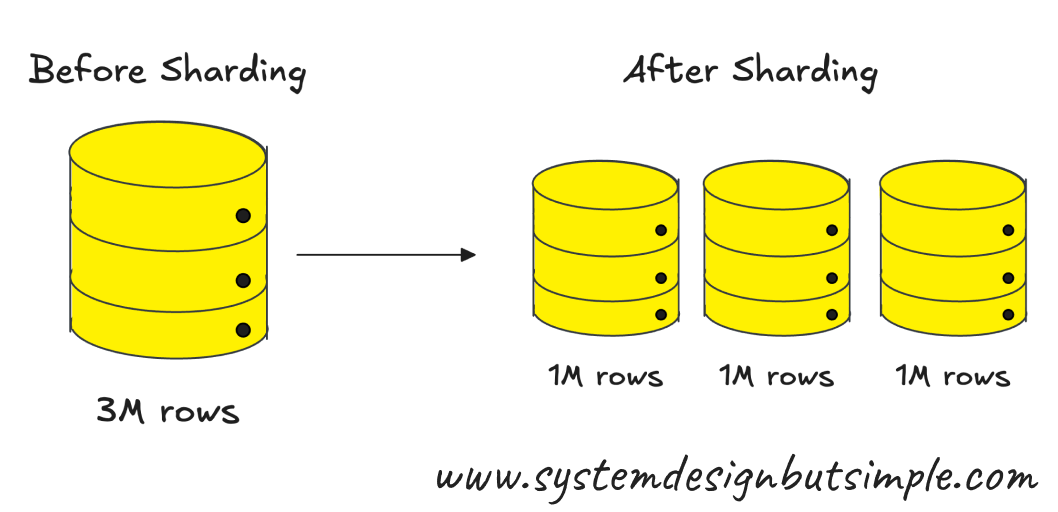
You need to know
- Shard key: Choosing the right shard key (e.g., user ID, region) affects data distribution and query efficiency. A bad choice can cause uneven load (a “hot shard”).
- Cross-shard operations are costly: Joins, transactions, or queries across shards are complex and slow – design to avoid them.
- Rebalancing is hard: Moving data between shards when traffic grows unevenly or hardware changes is tricky and can require downtime or complex tooling.
Popular algorithms
- Modulo-based Sharding – Data is assigned using
hash(key) % number_of_shards; simple but hard to scale (adding/removing shards reshuffles everything). - Range-based Sharding – Shards are defined by value ranges (e.g., user_id 1–1000); good for predictable access but risks uneven load if data isn’t uniform.
- Consistent Hashing – Maps data and shards to a ring; only a small portion of data moves when shards are added/removed.


