Hey there, fellow explorers of the AI world! You’ve probably heard a lot about Generative AI models, those amazing systems that can create text, images, and more. But what if these models could go beyond just generating content? What if they could actually do things in the real world, like book flights, manage your calendar, or answer questions by searching the web in real-time?
That’s where Generative AI Agents come in. They represent a significant leap forward from standalone models. Think of them as the next evolution, moving from systems that just produce output to systems that can actively work towards goals, much like a skilled assistant uses tools to get a job done.
This article is a beginner-friendly overview, distilling key concepts from two insightful Google whitepapers: Agents and Agents Companion. We’ll break down what agents are, how they work, the tools they use to interact with the world, and even peek into complex real-world applications like multi-agent systems.
By the end, you’ll not only understand how Generative AI agents work; you’ll also see why they’re so critical for next-gen applications, how to avoid common pitfalls, and how to evaluate them effectively.
What Are AI Agents?
At its heart, a Generative AI agent is an application designed to achieve a specific objective.
AI agents interact with their environment by observing, reasoning, and acting using tools and APIs.
Unlike a basic language model that just gives you a single answer based on its training data, an agent can reason, plan, and execute tasks autonomously. It can even figure out what it needs to do next to reach its goal without explicit step-by-step instructions from a human. This blend of reasoning, logic, and the ability to tap into external information is what defines an agent.
Think of a chef. A chef doesn’t just rely on their internal knowledge:
- they use tools (knives, ovens, recipes),
- gather information (customer orders, pantry contents),
- reason about the best way to prepare a dish,
- take action (chop, cook), and
- adjust based on feedback or changing circumstances.

Agents operate in a similar cyclical fashion.
How AI Agents Work: Core Architecture
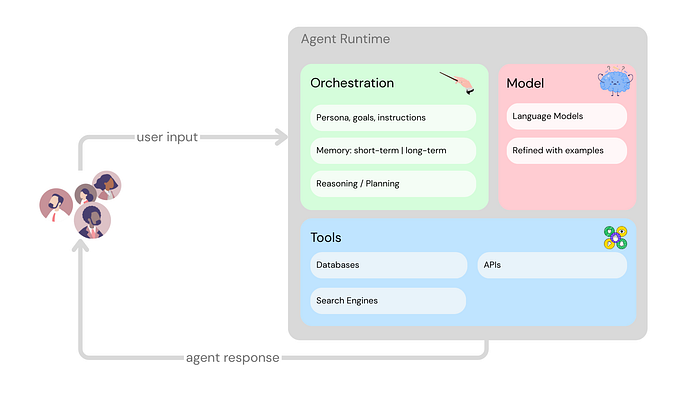
How does an agent manage this observation, reasoning, and action? It relies on a cognitive architecture, which can be broken down into three fundamental components:
- The Model: This is the brain of the agent, typically a language model (or potentially multiple models). The model is the central decision-maker, capable of following instruction-based reasoning. It’s not usually trained on the agent’s specific setup, but it can be refined with examples.
- The Tools: These are the agent’s hands and senses, allowing it to interact with the outside world beyond its training data. Tools bridge the gap between the agent’s internal capabilities and external systems like databases, APIs, or search engines.
- The Orchestration Layer: This is the manager or the process flow. It’s a cyclical loop that takes in information, performs internal reasoning, and uses that reasoning to decide the agent’s next action or decision. This loop continues until the agent reaches its goal. The orchestration layer is responsible for managing the agent’s memory, state, reasoning, and planning.
Together, these components allow agents to go far beyond just generating text. They can access real-time data, perform real-world actions, maintain conversation history, and execute complex tasks through multi-step processes.
Tools: The Agent’s Keys to the Outside World
Without tools, models are limited to the information they were trained on, which quickly becomes outdated.
Tools empower agents to connect to dynamic, real-world information and services. The sources highlight three primary types of tools Google models can interact with: Extensions, Functions and Data Stores.
Extensions
Think of Extensions as a standardized way to bridge an API and an agent. They teach the agent how to use a specific API endpoint and what arguments it needs, often using examples. The key here is that the Extension is executed on the agent-side. If a user wants to book a flight, the agent, using an Extension configured for a flight API, can make that API call directly.
Functions
Functions are similar to Extensions in that they connect the agent to external capabilities, but with a significant difference: the model outputs a Function call and its arguments, but the execution happens on the client-side. The agent doesn’t directly call the API; it tells the application what API call needs to be made and with what parameters. This gives developers greater control.
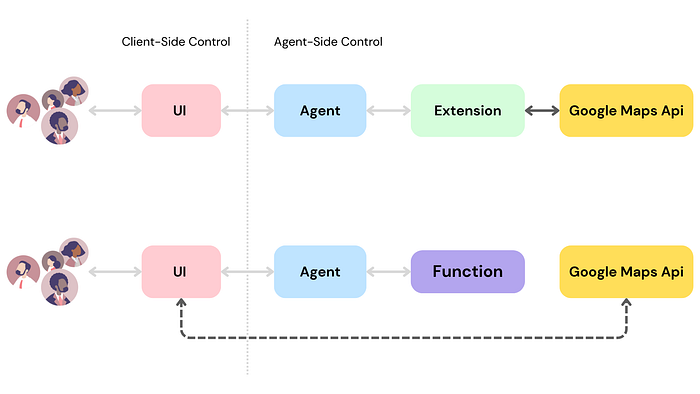
Delineating client vs. agent side control for extensions and function calling
Let’s look at a simple example.
Lets say we have an agent helping a user plan summer vacations. 🏖
The goal is to get the agent to produce a list of mediterranean islands that we can use in our middleware application to download images, data, etc. for the user’s trip planning.
A user might say something like:
I’d like to take summer vacations in an island with quiet beaches with my family but I’m not sure where to go.
In a typical prompt to the model, the output might look like the following:
Sure, here’s a list of mediterranean islands that you can consider for family summer vacations:
– Skopelos, Greece
– Santorini, Greece
– Crete, Greece
– Majorca, Spain
– Sardinia, Italy
– Corsica, France
While the above output contains the data that we need (island names), the format isn’t ideal for parsing. With Function Calling, we can teach a model to format this output in a structured style (like JSON) that’s more convenient for another system to parse.
Given the same input prompt from the user, an example JSON output from a Function might look like the following:
function_call {
name: "display_islands"
args: { "islands": [
{"name": "Skopelos", "country": "Greece"},
{"name": "Santorini", "country": "Greece"},
{"name": "Crete", "country": "Greece"},
{"name": "Majorca", "country": "Spain"},
{"name": "Sardinia", "country": "Italy"},
{"name": "Corsica", "country": "France"},
], "preferences": "quiet beaches"}
}This JSON payload is generated by the model but would be sent back to your application (the client-side) to then use these parameters to call a different API (like Google Places) to get more details or images, which are then displayed to the user.
This decouples the agent’s decision-making from the actual API execution.
The following sequence diagram shows the above interaction in step by step detail.
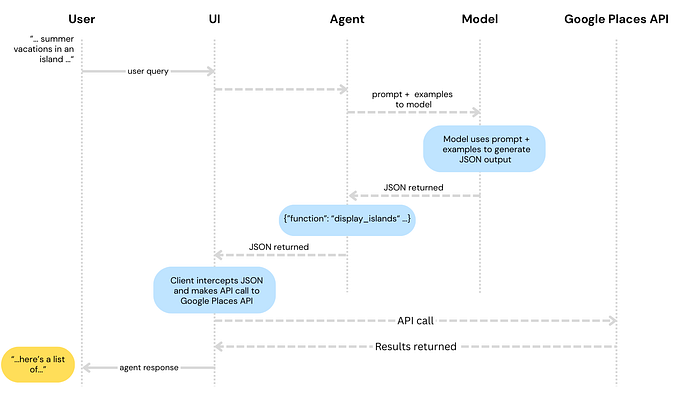
This example shows how the model identifies the user’s intent (“an island with quiet beaches”) and suggests calling the display_islandsfunction with the appropriate parameters. Your application code then receives this structured suggestion and performs the actual work.
Data Stores
Now, what if you need your agent to access up-to-date documents, websites, or databases that weren’t part of its initial training data?
Data Stores provide access to this dynamic information. They typically involve converting documents into numerical representations (vector embeddings) stored in a vector database. When a user asks a question, the agent can search this database for relevant information using the user’s query (also embedded). This retrieved information is then given to the agent’s model to help it formulate a grounded, factual response.
This is the core idea behind Retrieval Augmented Generation (RAG). Data Stores allow agents to extend their knowledge far beyond their static training data, using various formats like PDFs, spreadsheets, or website content.
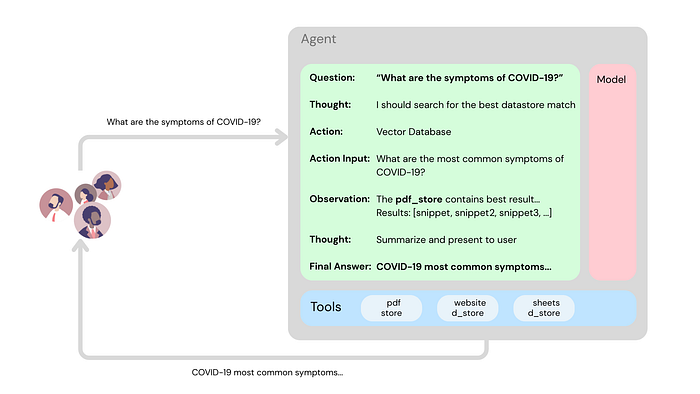
In summary, these tools are vital for enabling agents to interact with the real world, access fresh data, and perform actions that a standalone language model simply cannot.
Common Pitfall: One of the biggest mistakes in agent development is underestimating the tool setup. Without properly defined schemas or reliable APIs, the agent’s function calling can fail silently or hallucinate capabilities.
If you want to learn more about Embeddings and Vector Databases, check the following article:
How AI Agents Learn, Reason, and Improve Over Time
We touched on the orchestration layer as the “manager.” This layer uses cognitive architectures and reasoning frameworks to guide the agent’s steps. Just like our chef follows a process, an agent needs a structured way to think and act.
Reasoning frameworks provide this structure. The sources mention several popular ones:
- Chain-of-Thought (CoT): This involves breaking down a complex problem into intermediate steps, allowing the model to show its “thinking process”.
- Tree-of-Thoughts (ToT): This expands on CoT by exploring multiple possible “thought chains” or reasoning paths, useful for more strategic tasks.
- ReAct (Reasoning and Acting): This framework synergizes thinking (“Thought”) and performing actions (“Action”). The agent alternates between internal reasoning (what should I do next?) and taking actions (using a tool).
Read more about how ReAct works at the following link.
These reasoning strategies make the agent’s decision-making process interpretable, auditable, and more robust.
Choosing the right reasoning framework is part of effective agent design. For example, Tree-of-Thoughts is especially useful when the agent needs to explore multiple possible plans before choosing one, but it’s also computationally heavier and not always necessary for simple tasks.
Beyond the Single Agent: Multi-Agent Systems
While a single agent is powerful, complex tasks often benefit from a team approach. Multi-agent systems involve multiple specialized agents collaborating to achieve complex objectives. Each agent can be an expert in a particular domain, working together like a team of specialists.
This approach offers significant advantages:
- Enhanced Accuracy: Agents can cross-check each other.
- Improved Efficiency: Tasks can be done in parallel.
- Better Handling of Complex Tasks: Large problems are broken down.
- Increased Scalability: Add more specialists as needed.
- Improved Fault Tolerance: If one agent struggles, others can help.
- Reduced Hallucinations and Bias: Combining perspectives leads to more reliable outputs.
These agents work together using different design patterns:
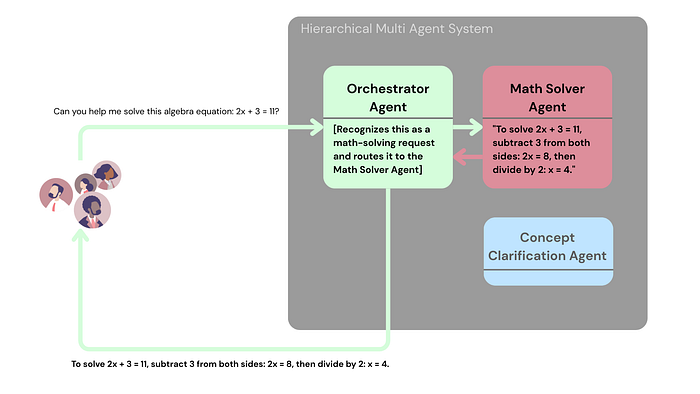
- Hierarchical: A central Orchestrator Agent routes queries to the correct specialized agent.
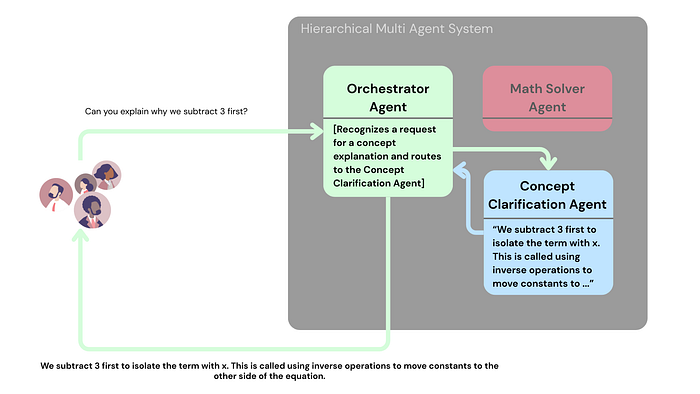
Diamond: Specialized agents’ responses go through a central agent (like a Rephraser) to refine the output before it reaches the user.
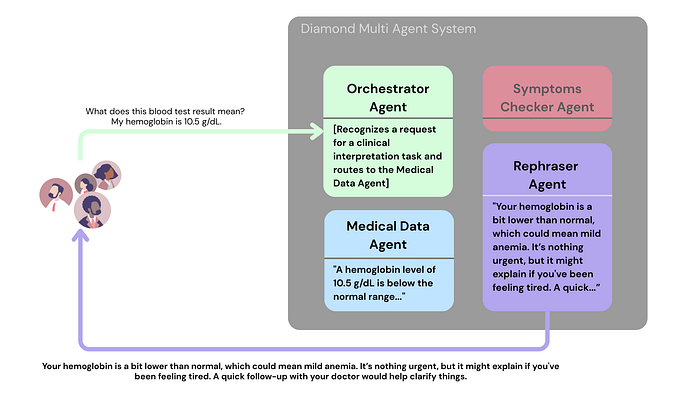
Peer-to-Peer: Agents can hand off tasks directly to each other if they realize a different agent is better suited.
- Peer-to-Peer: Agents can hand off tasks directly to each other if they realize a different agent is better suited.
Collaborative: Multiple agents contribute complementary parts to answer a single query, and a Response Mixer Agent combines them.
- Collaborative: Multiple agents contribute complementary parts to answer a single query, and a Response Mixer Agent combines them.
Adaptive Loop: An agent iteratively refines its approach through repeated attempts, adjusting queries or actions until satisfactory results are achieved.
Common Pitfall: While multi-agent systems offer flexibility, they introduce complexity. Poor coordination between agents can result in delays, inconsistent answers, or unnecessary tool use.
Building and Evaluating Agents
Getting agents from a cool idea to a reliable, production-ready application requires discipline. The sources introduce Agent Ops, a practice focusing on efficiently operationalizing agents, building on DevOps and MLOps.
But what does effective agent evaluation actually look like?
Why Evaluation Matters
Lets say your agent confidently tells a user that Santorini is in Italy. The output looks great: it’s structured, fluent, and fast. But it’s completely wrong.
So what failed? The reasoning? The tool? The retrieval step?
This is the value of deep agent evaluation; not just judging the output, but understanding how the agent got there.
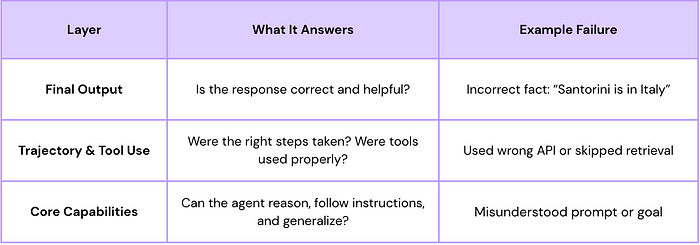
Evaluation involves:
- Assessing Core Capabilities: How well does the agent understand instructions or reason?
- Evaluating Trajectory and Tool Use: Analyzing the sequence of steps and tool calls the agent made. Did it take the expected path? Were the tool calls correct?
- Evaluating the Final Response: Is the final output correct, relevant, and high-quality? You can use automated tools (“autoraters” or LLMs acting as judges) or human evaluation for this.
Common Pitfall: While multi-agent systems offer flexibility, they introduce complexity. Poor coordination between agents can result in delays, inconsistent answers, or unnecessary tool use.
Building and Evaluating Agents
Getting agents from a cool idea to a reliable, production-ready application requires discipline. The sources introduce Agent Ops, a practice focusing on efficiently operationalizing agents, building on DevOps and MLOps.
But what does effective agent evaluation actually look like?
Why Evaluation Matters
Lets say your agent confidently tells a user that Santorini is in Italy. The output looks great: it’s structured, fluent, and fast. But it’s completely wrong.
So what failed? The reasoning? The tool? The retrieval step?
This is the value of deep agent evaluation; not just judging the output, but understanding how the agent got there.
Evaluation involves:
- Assessing Core Capabilities: How well does the agent understand instructions or reason?
- Evaluating Trajectory and Tool Use: Analyzing the sequence of steps and tool calls the agent made. Did it take the expected path? Were the tool calls correct?
- Evaluating the Final Response: Is the final output correct, relevant, and high-quality? You can use automated tools (“autoraters” or LLMs acting as judges) or human evaluation for this.
Metrics are key, from high-level business goals (like goal completion rate) down to detailed traces of the agent’s internal steps. Human feedback (like simple thumbs up/down or feedback forms) is also invaluable, especially for subjective tasks or calibrating automated evaluations.
Platforms like Google’s Vertex AI Agent Builder provide tools and services to help developers build, manage, and evaluate agents, including managed runtimes, evaluation services, and a portfolio of pre-built tools for databases, APIs, and search.
Top Tip: The most effective evaluations go beyond final outputs. Use trajectory tracing to find where agents make missteps, and combine autoraters with human feedback to get a complete picture of performance.
The Future is Agentic
Generative AI agents are ready to transform how we interact with technology and automate complex tasks. By using tools, reasoning frameworks, and collaborating in multi-agent systems, they can tackle problems far beyond the reach of standalone models.
The journey from prototype to production is still evolving, with ongoing research into better evaluation methods, multi-agent coordination, real-world adaptation, and making agent behavior more understandable. Concepts like “contract adhering agents” are being explored to make agent task definitions more precise and reliable.
Moreover, AI agents are increasingly used in industries like healthcare, automotive, customer service, and finance, with companies leveraging them to automate tasks and improve decision-making.
This has been a quick tour based on Google’s whitepapers, covering the fundamental building blocks and hinting at the exciting possibilities. If you’re curious to learn more, the sources themselves are packed with deeper insights, diagrams, and technical details.
This has been a quick tour based on Google’s whitepapers, covering the fundamental building blocks and hinting at the exciting possibilities. If you’re curious to learn more, the sources themselves are packed with deeper insights, diagrams, and technical details.
The agentic era is just beginning, and it’s one of the most exciting frontiers in AI today.
Want to go deeper? Search for terms like “Agentic RAG,” “LLM orchestration,” “function calling in GenAI,” and “Vertex AI Agent Builder”; these will surface more real-world examples and toolkits.